





HAProxyConf 2021:
Processing Millions of Payments Through a Cloud Native Infrastructure
Note: This blog post is based on material shared at HAProxyConf 2021 by Brendan Devenney and Piotr Olchawa.
Too long; didn’t read
- Kubernetes operators are literally magic.
- The HAProxy Data Plane API can be used for safe, dynamic, reproducible configuration - no need for any manual work!
- We built a Kubernetes operator to drive the Data Plane API, allowing us to dynamically configure live production load balanacers without fear!

Faster Payments Scheme
As a single-integration payment platform, it is our responsibility to integrate with a rapidly growing list of payment schemes across the world. From international SWIFT payments, to the Single European Payment Area, to a place closer to home – at least for me – in the Faster Payments System.

We recently delivered a presentation at HAProxyConf 2021 which recounted our quest to become a Faster Payments Gateway - more specifically how HAProxy helped us deal with a complex matrix of networking requirements, security controls, service level agreements, and maintenance schedules. The payments industry is very heavily regulated due to the extraordinarily high stakes.
Note: The important word to remember throughout this post is “faster”. Faster Payments must be handled in seconds or they will be reversed (returned to sender). There is no room for downtime as downtime has real impact on both the end users and the participant’s brand.
Faster than what?
The Faster Payments Service interconnects banks in the UK, with its key aim being to reduce bank-to-bank transfer times from the three days in case of BACS – or the “by end of working day” in case of CHAPS - to only a few seconds. You can see the stark contrast in requirements already; the FPS scheme is very ambitious, but also more aligned with the modern world. As such, the scheme expects gateways and participants to be always-on.
The stats speak for themselves: the scheme processed over 2.9 billion payments with a combined value of over £2.1 trillion in 2020[ref], with Form3 trending towards 400 million payments processed in 2021. I will leave you to do the maths and work out the percentages here, otherwise I will never sleep again!
Main actors
The Faster Payments System has three main actors:
- Participants: the banks which act on behalf of their customers. They connect to a gateway in order to send and receive payments.
- Gateways: the systems which connect Participants to the Central Infrastructure. In some rare cases, Participants are also Gateways, such as Monzo who famously built their own gateway to take full control of their destiny.
- Central Infrastructure: Sometimes simply referred to as “the scheme,” this is the core of the Faster Payments System through which all payments flow. It is the single source of truth, the ledger, and the deity that we all pray to before bedtime.
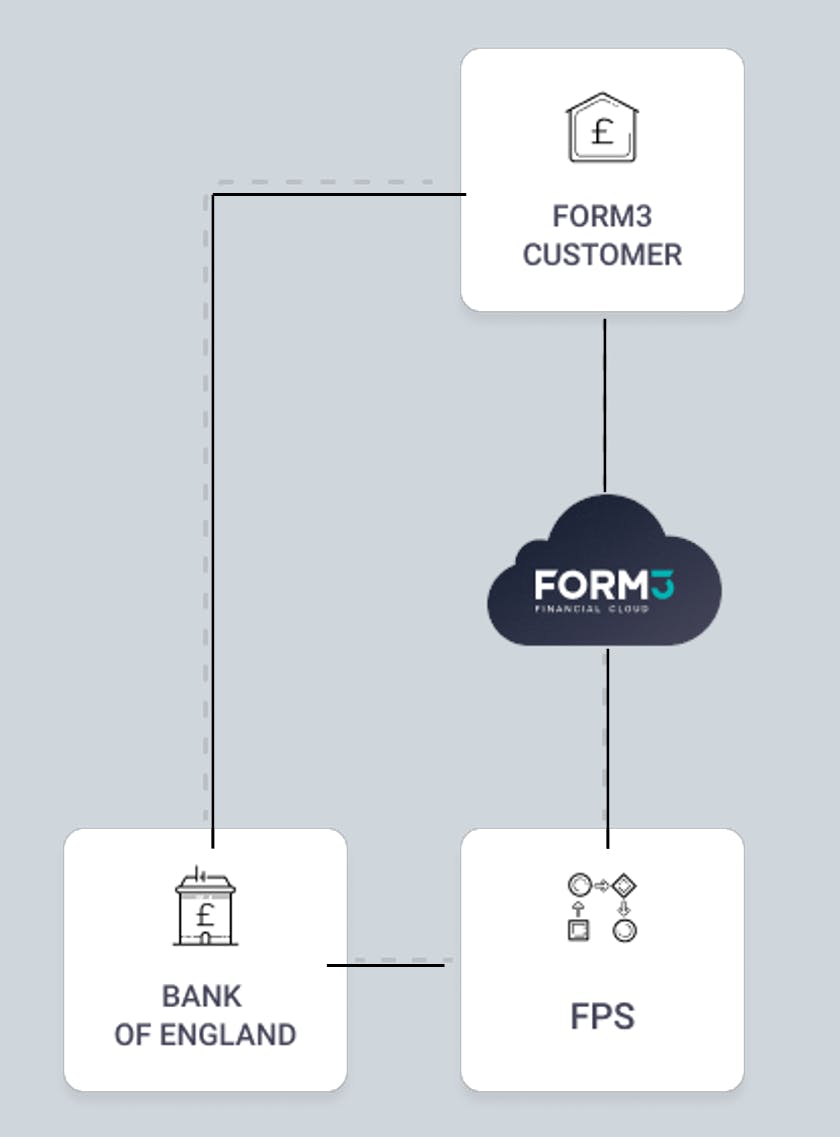
To keep things simple, we will ignore the Bank of England – probably the only time in my career I will ever be able to say that. For the context of this discussion, keep in mind that Form3 act as agateway. This means we have to worry about both Central Infrastructure (Scheme) and Participant connectivity.
Scheme Connectivity
Integration with the Central Infrastructure is based on persistent connections. These connections are evenly distributed across two data centres for redundancy, but that does not mean we can happily tolerate losing any of these connections.
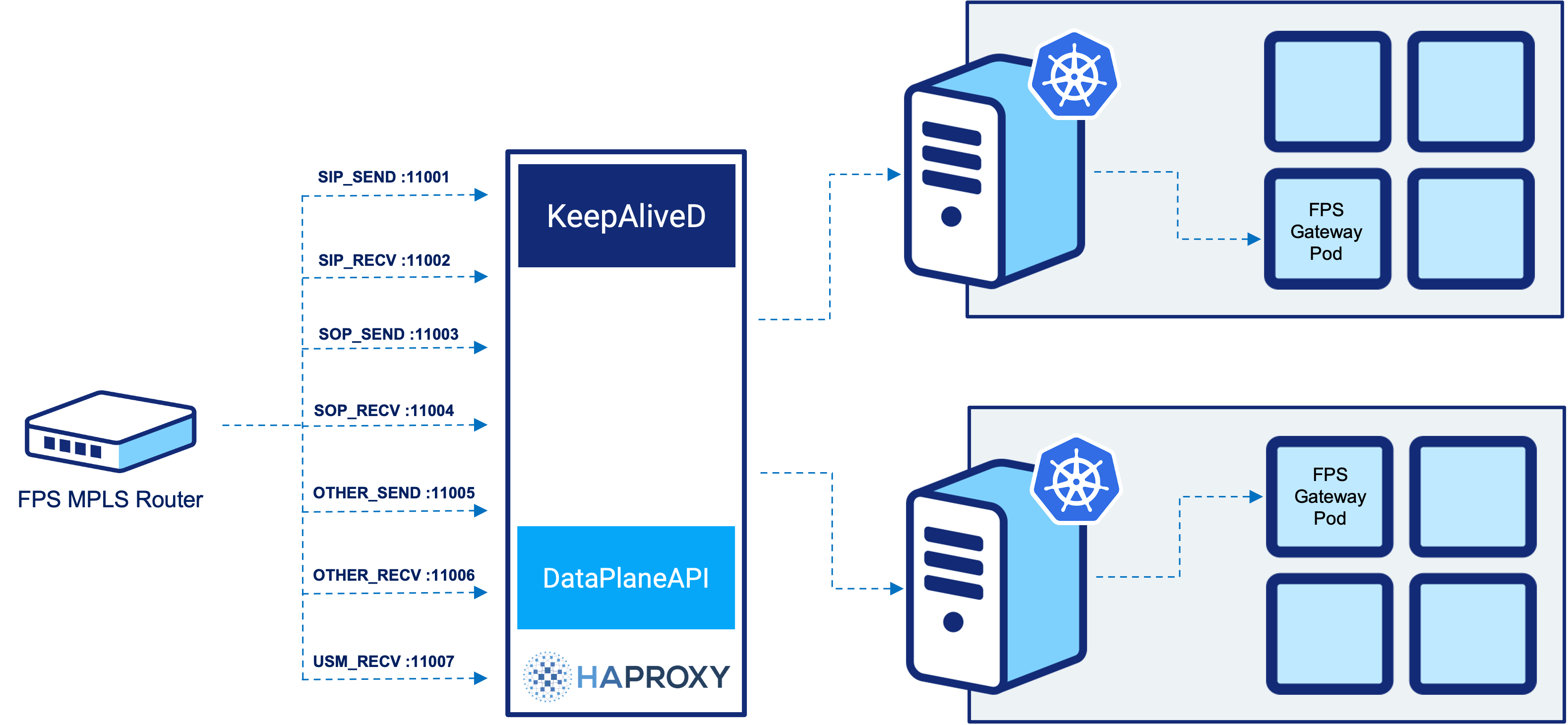
All requests must be responded to on the exact connection they were received on. If the connection disappears between the two phases, the payment is lost to the ether. This generally leads to a reversal. That is, an end user sees a transaction fail - bad for them and bad for their trust in the bank.
Participant Connectivity
On the participant side of the connectivity problem, our architecture requires all traffic to ingress to a single site. This gives us an “open” and a “closed” site. There must always be exactly one open site for the MQ solution to remain operational. MQ itself also uses persistent connections - the architecture is based on unidirectional channels which, when interrupted, cause a complete outage. The death of an MQ channel is equivalent to the death of an HTTP(S) server.
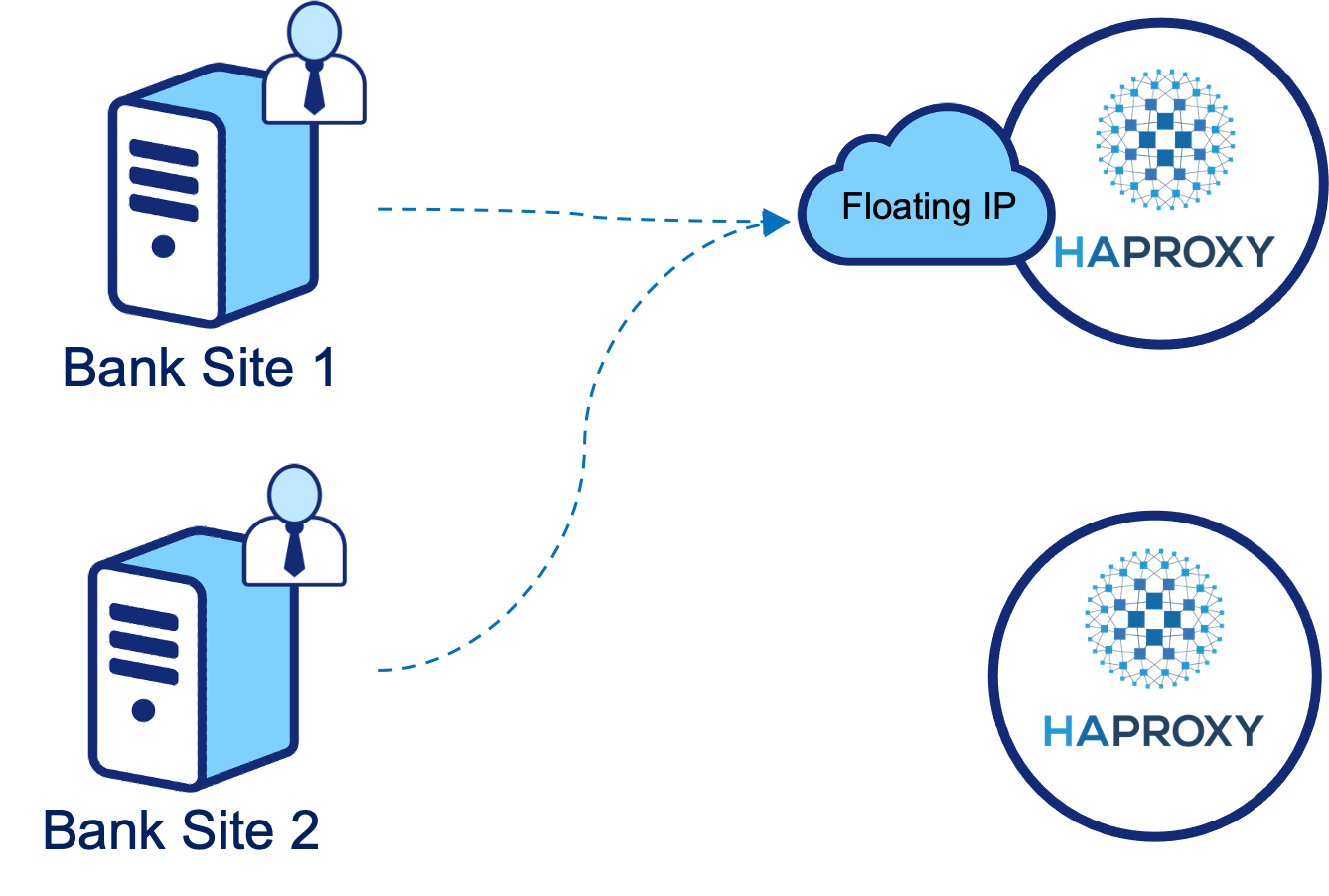
To ensure that we have one open site at any given moment, we use the Virtual Router Redundancy Protocol (VRRP). This turns a collection of servers into a virtual router in which, at any time, exactly one member is the master.
Isn’t this an HAProxy article?
These virtual routers sit at the edge of the DMZ between Form3 and the extranet (a private network shared with the scheme and our participants). This, unfortunately, rules out the use of the HAProxy Kubernetes Ingress Controller as our HAProxy nodes exist outside of our processing clusters. For those of you who like to skip to the end of a story, a spoiler: we wrote our own controller!
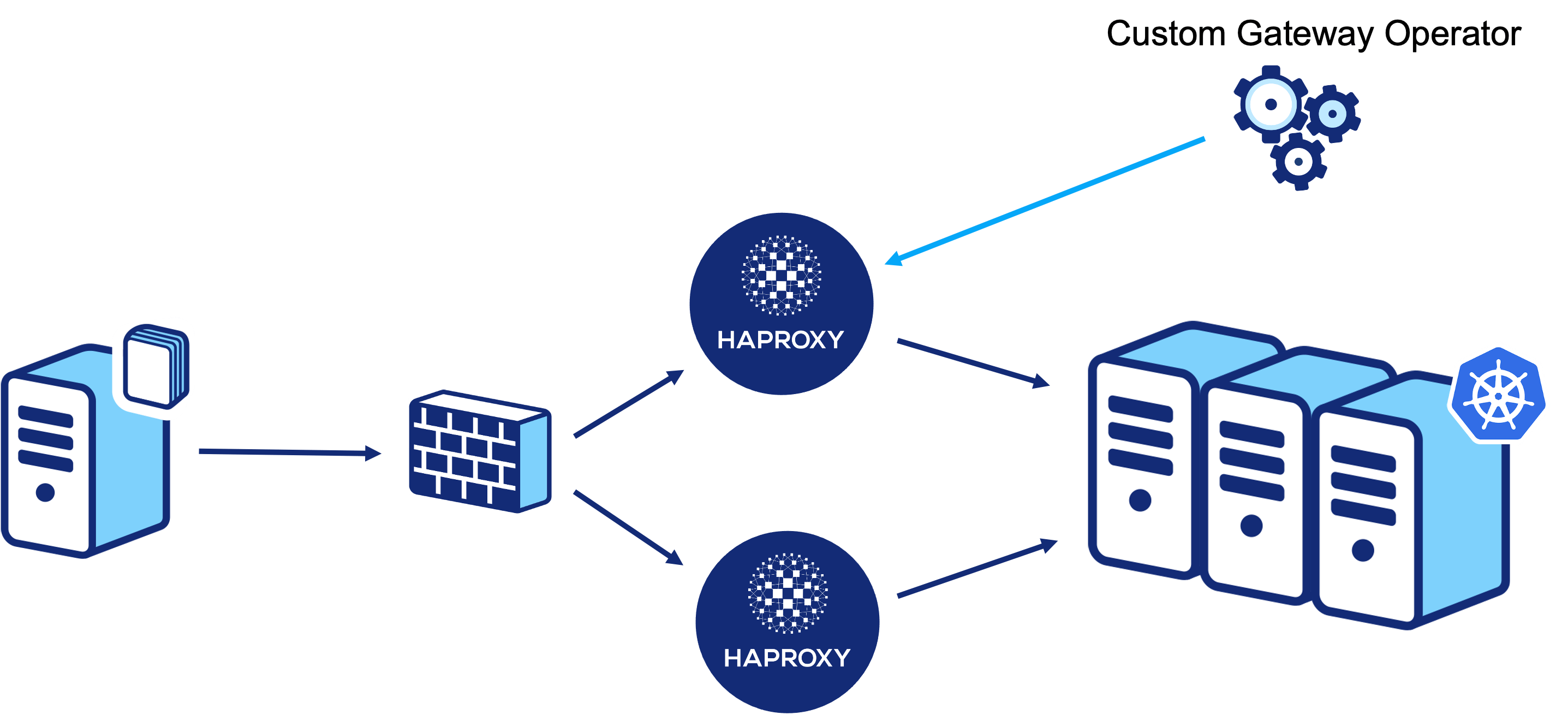
After passing through the firewall to the DMZ, traffic will be routed to the HAProxy installation at the “open” site. This will then forward the traffic onto the relevant nodes in our Kubernetes cluster.
How, then, do we dynamically configure HAProxy to be aware of our ever-changing Kubernetes cluster and ensure that this configuration survives scorched earth rebuilds?
Data Plane API
As some of you will be aware, it is possible to achieve API-driven configuration of HAProxy via the Data Plane API. This runs as a sidecar process, translating API payloads into configuration changes on-disk and managing process reloads when necessary.
The Data Plane API maintains all of the HAProxy terminology we are familiar with – frontends, backends, servers – but also provides some abstractions to ease the burden of management. One such concept is the SiteFarm – an abstraction which makes it extremely easy to create a simple “site” with multiple backend servers. Depending on your use case, these abstractions may help or hinder – configurability is sacrificed in favour of this frictionless usage.
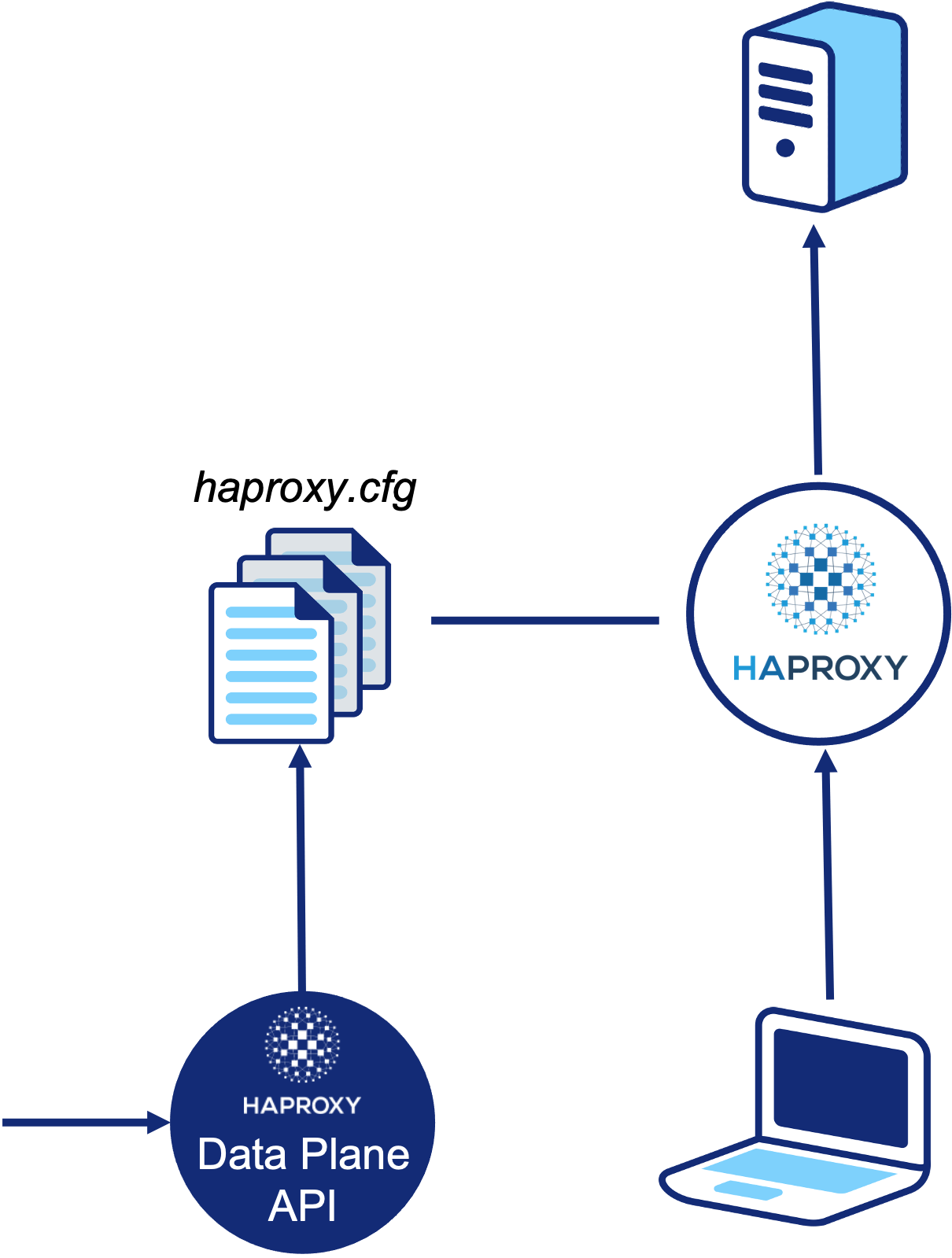
On top of this, the Data Plane API is transactional. The user can build multiple changes into a single transaction – for example, you wish to delete one backend server and add another – and commit these all at once. In this example, without transactions, this could result in old backend servers being removed without new ones being added. Transactions make changes to running load balancers safe.
Kubernetes Operators
Now, an abrupt change of topic – but I promise it will come together soon. Kubernetes operators.
Human operators who look after specific applications and services have deep knowledge of how the system ought to behave, how to deploy it, and how to react if there are problems People who run such workloads - on Kubernetes or otherwise - often make use of automation to take care of repeatable tasks.
The Kubernetes Operator pattern captures how you can write code to automate a task beyond what Kubernetes itself provides. The pattern aims to capture the key aim of a human operator who is managing a service or set of services.
Kubernetes Operators make use of the control loop. In robotics and automation, a control loop is a non-terminating loop that regulates the state of a system. One example of a control loop is a thermostat in a room. When you set the temperature, you are telling the thermostat about your desired state. The actual room temperature is the current state. The thermostat acts to bring the current state closer to the desired state, by turning equipment on or off. In our case, we refer to this at observing the state of HAProxy configuration, calculating the difference between observed state and desired state, and updating the HAProxy configuration to align.
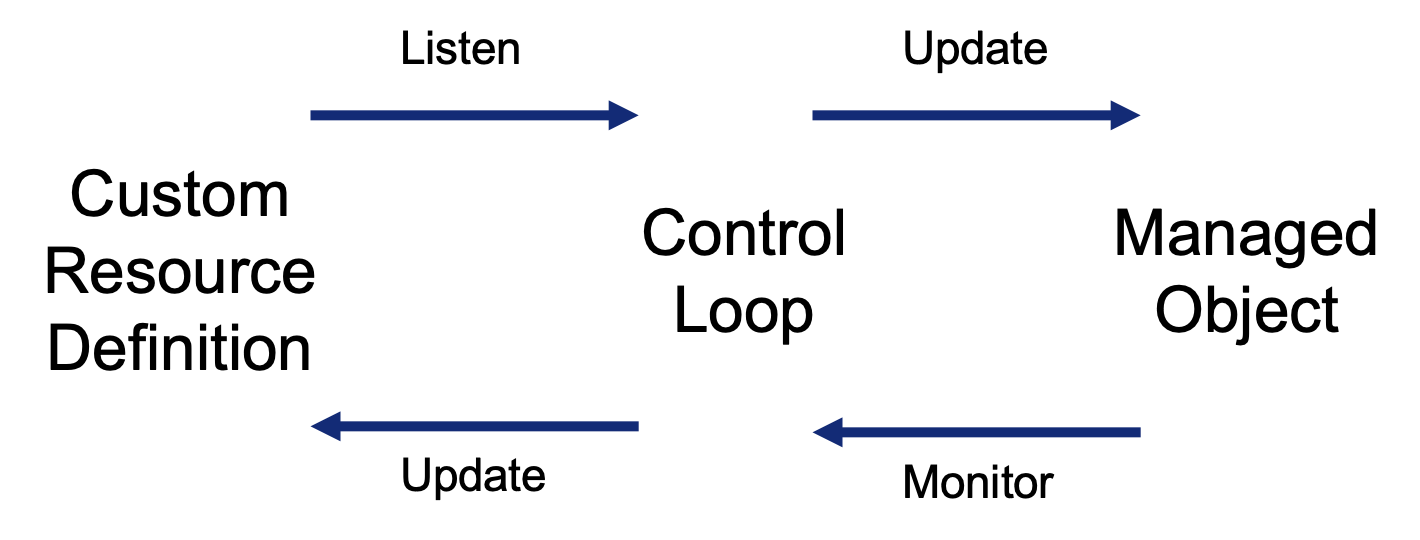
But how do we know the desired state in such a complex architecture?
Custom Resource Definitions
The missing link here is Kubernetes custom resource definitions. Fundamentally, custom resources are extensions of the Kubernetes API that are not necessarily available in a default Kubernetes installation. It represents a customization of a particular Kubernetes installation. However, many core Kubernetes functions are now built using custom resources, making Kubernetes more modular.
On their own, custom resources let you store and retrieve structured data. When you combine a custom resource with a custom controller, custom resources provide a true declarative API. That is, you declare the desired state of your resource and the controller keeps the current state in sync with your declared desired state. This is in contrast to an imperative API, where you instruct a server what to do.
The Result: Dynamic HAProxy Configuration
In our use case:
- We declare, at a high level in YAML, the desired state of a given organisation’s network ingress, egress, and security configuration.
- The operator observes that an Organisation resource has been created or updated.
- The control loop ensures that our low-level HAProxy config matches our high-level declared desired state.
- The operator updates our Organisation resource with fields such as finalizers which we will see in our upcoming demo.
Thus, any undesired change to our HAProxy configuration – a virtual machine rebuild, a manual change, etc. – will be detected and rectified by the control loop. This gives us a repeatable, automated, reliable, and easily maintainable translation layer from business requirements to HAProxy configuration.
If you’re interested in learning more, feel free to reach out to Brendan or Piotr via LinkedIn!
Written by



Brendan is a software engineer with a history of defensive programming in high-value environments. He has had an eclectic career path from embedded software instrumentation and performance engineering, through API security and cloud platform architecture, to building the future of banking.
Read more
Blogs · 10 min
Dangling Danger: Route53's Flawed Dangling NS Record Protection
A subdomain takeover is a class of attack in which an adversary is able to serve unauthorized content from victim's domain name. It can be used for phishing, supply chain compromise, and other forms of attacks which rely on deception. You might've heard about CNAME based or NS based subdomain takeovers.
October 27, 2023
Blogs · 4 min
Applying the Five Ws to Incident Management
In this blogpost, David introduces us to the five W's of information gathering - Who? What? When? Where? Why? Answering the five Ws helps Incident Managers get a deeper understanding of the cause and impact of incidents, not just their remedy, leading to more robust solutions. Fixing the cause of an outage is only just the beginning and the five Ws pave the way for team collaboration during investigations.
July 26, 2023
Blogs · 4 min
.tech Podcast - All about conference speaking
Patrycja, Artur and Marcin are engineers at Form3 and some of our most accomplished speakers. They join us to discuss their motivations for taking up the challenge of becoming conference speakers, tell us how to find events to speak at and share their best advice for preparing engaging talks. They offer advice for new and experienced speakers alike.
July 19, 2023