





Network Address Translation (NAT) and Proxies (part 2)
Exposing pools of machines to clients, or routing network traffic via an intermediary, are common techniques in distributed computing, and large networks. Network Address Translation, forward proxies, and reverse proxies, are three common techniques for managing network traffic at scale. However, I've always found each of these topics to be somewhat mystical, and I've never understood the fundamentals of how each technique works.
In this blog post, I will attempt to distil each idea into its simplest form, and write a code example where possible.
The first blog post on this topic covered:
- Introduce TCP/IP at a high level, and demonstrate TCP communication in Go.
- Take a deeper look at IP communication, and the Linux networking stack.
- Introduce Network Address Translation, and illustrate how it works.
This second part will:
- Examine forward proxies, and show a simple example in Go.
- Examine reverse proxies, and show a simple example in Go.
- Summarise the differences and similarities between NATs and proxies, and provide examples of their use cases.
Forward proxies
Whereas NAT is implemented at the network-layer (i.e. at the IP layer, beneath TCP), proxies operate at the application-layer (e.g. HTTP). This means that proxies are normally specific to the protocol you intend them to operate on. In the examples below, I'll look at HTTP proxies, although proxies could be used for other protocols as well.
An HTTP proxy acts an intermediary between the client sending the request, and the server receiving the request. Unlike NAT, which transparently modifies network packets, a proxy accepts and terminates network connections, and then re-transmits requests to the destination.
This means that, when you make requests via a proxy, the proxy actually accepts and processes the request, before making a new request on your behalf to the downstream server.
Unlike NAT, this is very easy to illustrate in a simple Go application, because all of the work happens at the application layer. Here's a sample application:
package main
import (
"io"
"net/http"
)
func main() {
// The proxy handles all HTTP requests.
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
// The proxy makes a new request using the same HTTP verb and
// relative URL as the original request. For simplicity, the body
// is excluded, so in practice this would only work for GET
// requests.
req, err := http.NewRequest(r.Method, r.RequestURI, nil)
if err != nil {
panic(err)
}
// The proxy sends a new request, on behalf of the original
// client.
res, err := http.DefaultClient.Do(req)
if err != nil {
panic(err)
}
// The response is read by the proxy.
body, err := io.ReadAll(res.Body)
if err != nil {
panic(err)
}
defer res.Body.Close()
// The contents of the proxied request are then written back
// to the HTTP response of the original client's request.
w.WriteHeader(res.StatusCode)
w.Write(body)
})
http.ListenAndServe(":8080", nil)
}This simple example handles all web requests by:
- Reading the request.
- Sending a new HTTP request that looks like the one it received.
- Reading the response to this request.
- Sending the same response back to the original client.
In reality, this is a very simple example (it will only work for GET requests among other things). However, it does illustrate the following main points:
- Network packets are not handled transparently by the proxy.
- Network traffic is processed at the application layer by the proxy.
- TCP connections are terminated from the client by the proxy.
- New connections are made downstream from the proxy to the destination.
Whilst this is a very different approach to NAT, it does have the same effect of masking the source IP address from the destination server's point of view. Since all requests are re-originated from the proxy, it is the proxy's IP address that will appear as the source IP address, at least at the network layer. Whether or not the same is true at higher levels of the network stack (e.g. in HTTP headers) depends on your implementation, but forward proxies like this can also be used to mask source IP addresses for many of the same reasons as NAT.
Forward proxies
- Forward proxies operate at the application-layer.
- They receive and terminate network-level traffic, e.g. TCP connections.
- Forward proxies make onward requests on behalf of the original client, so the requests appear to originate from the proxy.
Reverse proxies
A reverse proxy operates in much the same way as a forward proxy, except that the address that is proxied is configured in advance in the proxy, rather than being dynamically based on the client's request.
When a request is sent to a forward proxy, the request is forwarded on to the original recipient indicated by the client's HTTP request. When a request is sent to a reverse proxy, the proxy decides where to forward the request based on some predetermined configuration.
This makes reverse proxies useful for presenting a public IP address for a set of private resources, like a set of private, back-end servers.
This is illustrated in the following simple Golang application:
package main
import (
"io"
"net/http"
)
func main() {
// The proxy listens for all HTTP traffic.
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
// The proxy handles the request by performing a pre-determined action. In
// reality, it is likley to forward the request to another upstream server,
// but in this example it simply makes a request to Google on behalf of
// the original client.
req, err := http.NewRequest(http.MethodGet, "https://www.google.com", nil)
if err != nil {
panic(err)
}
// The proxy makes the request on behalf of the client.
res, err := http.DefaultClient.Do(req)
if err != nil {
panic(err)
}
defer res.Body.Close()
// The proxy copies the contents of the proxied response into
// the response to the original client's request.
w.WriteHeader(res.StatusCode)
_, err = io.Copy(w, res.Body)
if err != nil {
panic(err)
}
})
http.ListenAndServe(":8080", nil)
}In this example, all requests to the reverse proxy are forwarded to https://www.google.com. This forwarding URL represents the static configuration that will determine how your proxy will route requests. If I run this example locally, and then curl -v http://localhost:8080, the Google home page is returned.
Reverse proxies
- Reverse proxies operate at the application-layer.
- They receive and terminate network-level traffic, e.g. TCP connections.
- Reverse proxies make onward requests on behalf of the original client according to a set of pre-defined rules.
Summary
This two-part blog post has described the behaviour and characteristics of Network Address Translation, forward proxies, and reverse proxies. This is summarised below:
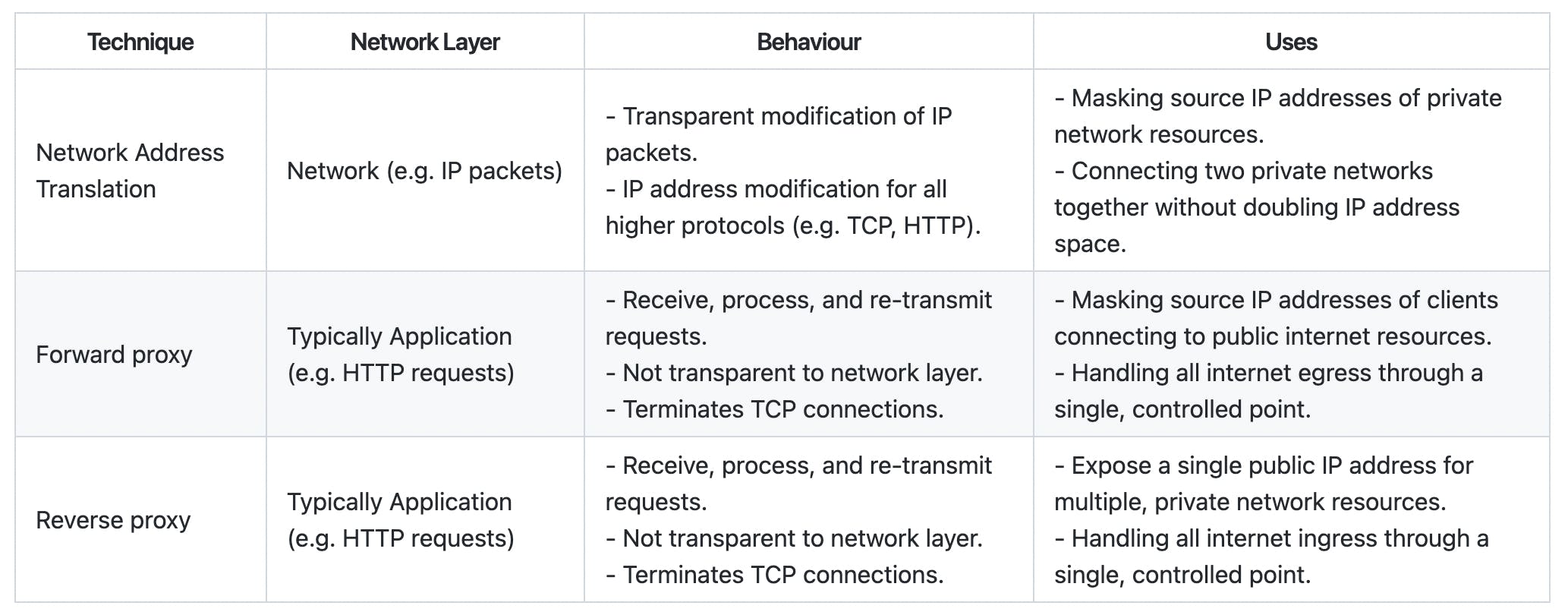
I hope you found this blog post useful in understanding these three networking techniques in the future, and you now consider them somewhat less mystical!